数据依赖症:当今AI领域的核心风险
摘要: 在最近结束的2017年度AI星际争霸竞赛上,Facebook做出了一款人工智能“CherryPi”,参与到这项旨在让各路AI技术在星际争霸游戏中同场竞技的赛事之中。
在最近结束的2017年度AI星际争霸竞赛上,Facebook做出了一款人工智能“CherryPi”,参与到这项旨在让各路AI技术在星际争霸游戏中同场竞技的赛事之中。

但很遗憾的是,Facebook仅仅获得了赛事的第六名,最直接的原因,在于Facebook坚持在CherryPi的研发中主要使用机器学习技术,而非像其他大多数参与者那样使用纯粹的预设编码脚本。预设编码脚本即通过人工方式预编程了非常复杂的游戏策略脚本,让程序根据脚本按图索骥机械式执行游戏。面对这些实际上并不能称为人工智能的对手,Facebook自家主要基于AI技术的CherryPi基本处于劣势,最终仅能获得第六名。随便提一下今年这项赛事的获胜者是一名对星际争霸游戏本身有深刻理解的业余人士所编制的脚本机器人(300024) 。当然Facebook的失败并不意外,因为目前要纯粹靠人工智能去挑战携带了大量人类游戏先验知识的脚本机器人,本身就是一场不对等的较量。
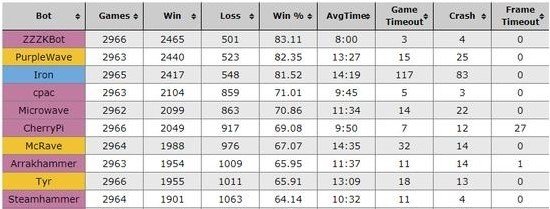
(2017年星际争霸AI大赛排行榜)
如果说Facebook的人工智能技术虽然最终未能取得好成绩,但尚且能和人类精心编制的脚本机器人一战的话,那发明了AlphaGo的DeepMind目前则被星际争霸2彻底玩坏了。
DeepMind与星际争霸2
此前,DeepMind和星际争霸系列制作公司暴雪联合推出了星际争霸2的机器学习平台sc2le,DeepMind借此希望在继AlphaGo后在星际争霸2上继续挑战人类,但令人失望的是,目前DeepMind在星际争霸2上进展缓慢。在今年7月底,DeepMind发表了一篇论文《StarCraft II: A New Challenge for Reinforcement Learning》系统阐述了他们在星际争霸2中的进展,在论文中DeepMind承认了目前的深度学习与增强学习框架在星际争霸2中并无任何理想的结果(...However, when trained on the main game, these agents are unable to make significant progress),AI甚至还远远比不上游戏自带的简单电脑(很弱的脚本机器人)。既然在全局游戏中表现非常差,DeepMind不得不退而求其次,设计了7个星际争霸2的迷你游戏,包括:
1. 寻路(“MoveToBeacon”);
2. 收集散落水晶(“CollectMineralShards”);
3. 寻找并消灭小狗(“FindAndDefeatZerglings”);
4. 消灭蟑螂(“DefeatRoaches”);
5. 消灭小狗和毒爆虫(“DefeatZerglingsAndBanelings”);
6. 收集水晶和气(“CollectMineralsAndGas”);
7. 训练机枪兵(“BuildMarines”);
在上面难度相当于Atari小游戏的迷你任务中,DeepMind的人工智能的表现才勉强达到合格线。下图是DeepMind在论文中总结的任务得分数据,在寻找并消灭小狗和消灭蟑螂游戏中AI接近、超越了普通人类玩家(DeepMind 自家工作人员),在寻路上接近了人类高手。
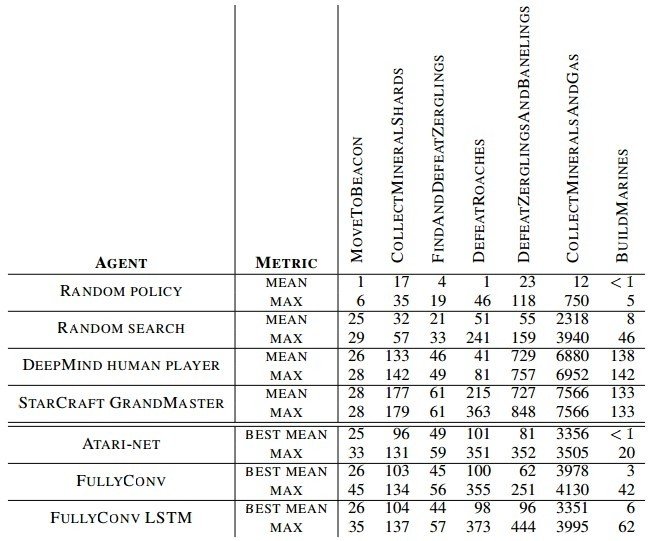
(DeepMind在7个迷你游戏的表现得分)
然而,上述7个迷你游戏相对于星际争霸2的全局游戏相差悬殊,DeepMind通过迷你游戏的设计将星际争霸2人工智能试验降低到Atari小游戏级别的难度,并不意味着人工智能在星际争霸2这款类似人类现实世界对抗/战争简化模拟的游戏上有太多显著的突破。而究其原因,在于星际争霸2的决策空间巨大,涉及了在收集资源、建设建筑、训练部队、局部战术等方面的海量决策,其决策空间远高于只有落子一个动作的围棋。另外更要命的是,RTS游戏由于进程较长,其策略的回报(reward)趋向长期,即意味着难以定义类似于Atari游戏中Agent非常明确的回报,这使得DeepMind在Atari游戏中屡试不爽的Reinforcement Learning变得难以凑效。
于是DeepMind似乎希望后续把研究回归到传统的监督学习方向,借助海量的星际争霸2人类玩家对局replay数据去优化学习的效果。在论文中通过replay增强学习后,Agent在采矿和造兵上等任务上相比此前自学有了显著的提升。
之所以说了这么多AI与星际争霸2的事情,是因为从中我们可以看到一个关键性的现象:在类似于星际争霸2这种复杂任务(决策空间巨大)之中,在计算机视觉、机器翻译、语音识别等领域取得了巨大成功的主流深度学习方法,事实上难以取得太多的成果,甚至连DeepMind也承认,在星际争霸2的尝试中他们遇到的困难远远高于此前的估计。而这是因为,当前的主流深度学习方法并不完美,其一切都是建立在海量的训练数据基础上。
算法不够,数据来凑
众所周知,目前深度学习在人工智能中所取得的成功,实际上建立在三大驱动因素上:算法、数据和算力。首先主流的深度学习算法近年来变化越来越少,同时深度网络的架构本身似乎对于效果的产出正在减弱,而真正让主流深度学习方法在计算机视觉、机器翻译、语音识别等领域取得了巨大成功的关键驱动力是数据。深度学习区别于传统机器学习方法的最大特征,是深度学习可以使用海量的数据去提升自身的表现(Performance),这可以用一幅经典的图表去展示。下图中横坐标是使用的训练数据量,纵坐标是算法表现,传统的机器学习算法往往在数据量超过一定的阈值后,其表现就难以继续随着训练数据量而提升,更多的数据输入仅仅是浪费;而大型的深度神经网络模型犹如一只大水桶,在装入了更多的数据后其表现能够继续攀升,数据成为了深度学习的核心驱动力,缺乏了海量的标注数据,深度学习的效果并不会比传统机器学习方法有太大的改善。而最后算力是保障如此巨大的海量数据(603138)能跑在深度学习框架上的基础能力,从某种角度理解NVIDIA的股价,是建立在数据科学界需要将海量数据注入深度神经网络并进行大量前向/方向传播的基础上。
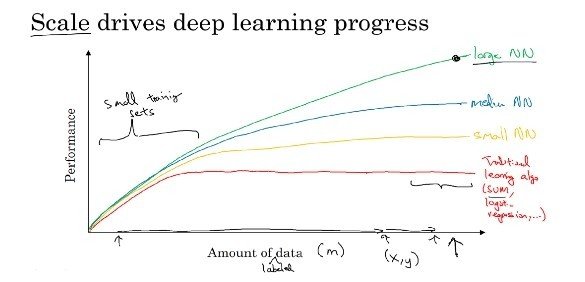
(来源于Andrew Ng神经网络和深度学习课程)
甚至,我们能以以下公式描述当今的人工智能业态:
当今人工智能 = 海量的标注数据 + 简单粗暴的前向/后向传播计算
于是AI界开始了标注数据收集的军备竞赛,类似Amazon Mechanical Turk的数据标注众包平台不断涌现,而自身具备了海量数据资源的BAT或者搜狗,一夜之间在语音识别准确率上纷纷接近甚至超越了在语音识别深耕了超过十年的科大讯飞(002230) 。标注数据的价值,让大数据时代一句经典的话——“数据即将成为新时代的电力”变得前所未有的真实。一个个如ImageNet等人工智能竞赛中不断被打破的准确率记录,其背后是无数的人力物力被投入到高质量的标注数据之中,人工智能一定程度上,甚至可以理解为有多少人工,被投入到数据标注之中,就能有多少智能。
然而,过分依赖海量标注数据的主流深度学习方法目前面临了越来越多的挑战,首先在某些标注数据难以收集或者收集代价很大的领域,让AI应用的建立变得举步维艰,比如在智慧医疗中,高质量的医学影像标注数据收集门槛非常高。另外更为重要的是,海量标注数据+深度学习框架+GPU并行计算的简单粗暴模式,在越来越多领域被证明或许没有大家想象的那么管用,上一节DeepMind在星际争霸2中的努力是其中一个案例。
究其原因,当下主流的深度学习方法或许并不是最优的范式。目前有越来越多的人在反思深度学习的局限和缺陷,甚至包括了深度学习之父Geoffrey Hinton本人。大多数学习过深度学习的人基本都练习过经典的cats vs dogs(猫狗大战)数据集,即从数万张已标注的猫咪和狗狗照片,训练神经网络判断一张图片的类别。但对于人类而言,我们并不需要如此大量的标注去让我们学习一种动物是猫咪,即使对于一个从来不知道猫的幼儿,在见过几次猫之后就能认知到这种实际上是一种区别于其他动物的物种,哪怕不知道它的语言名称,当某一天有人告诉她这种生物叫“猫咪”后,只需要这一次“标注”(One-shot learning),她以后就能准确分辨出每一只猫。然而对于当前深度学习来说,依赖的是大量的数据标注,这种One-shot learning是极其艰难的挑战。
在这里,我们能总结性地说一句,大数据让深度学习插上了腾飞的翅膀,但同样也成为了深度学习飞翔到更多领域的障碍。毕竟在很多领域海量的标注数据不是那么容易获取,甚至“标注”本身也是一项极其难定义的事情,比如在星际争霸2中,我们应该如何更好地标注replay数据,让AI能更好地进行监督学习?甚至进一步说,这种标注行为也许并不是一个明智的选择,正如人类并不需要在学会玩星际争霸之前,首先得看成千上万场别人的replay去学习各种玩法。
人工智能的下半场
在计算机视觉、机器翻译、语音识别等标注数据获取相对代价低廉的领域,诚然我们看到了主流深度学习方法所取得的巨大成功,这不仅是孜孜不倦积累30多年的深度神经网络技术的集中爆发,也使得深度学习引领人工智能进入了目前的炽热状态。但必须实事求是地说,越来越多的证据表明,当前主流深度学习方法也许并不是一项普适性技术,在更多类似星际争霸2等任务极其复杂、数据难以标注的领域,也许我们需要的是新的方法。
深度学习之父Geoffrey Hinton最近公开号召摒弃现有深度学习(主要是反向传播、CNN)范式,重新奋力向前寻找全新的道路。Hinton认为,要想让神经网络能够自己变得智能,即实现不依赖海量标注数据的“无监督学习”,意味着需要放弃反向传播等目前主流深度学习理念。对于在深度学习领域中,地位犹如爱因斯坦于物理学界的Hinton,要质疑甚至推翻自身花费了十几年心血所建立的主流深度学习方法,必然是需要具备极其巨大勇气的,我们甚至可以合理推测,Hinton老爷子心中必定是对人工智能未来有了新的vision,才能驱使他坚定地做出如此艰难的选择。

当然,也许只有类似Hinton等极少数人才能拥有对于未来技术演进的vision,但立足于对当前业态的观察,我们也能发现目前主流深度学习的势能似乎已经在逐渐减弱,也许这就是当前人工智能业界最大的风险所在。
海量的标注数据,加上简单粗暴的前向/后向传播计算,也许并不是人工智能未来的全部,从今天开始,我们最好把这点记在心中。
数据依赖症

















